Defining digital
We’ve been talking a lot about making collections available online. In some cases we’re just talking about publishing the metadata, such as in a library catalogue or an archival finding aid. But increasingly there’s an expectation that the full content of collections will be made available in digital form – that we can access books, photos, sound and video with just a simple click. But what are digital collections, and how do we create them?
First we need to distinguish between two broad types of digital objects – those that are ‘digitised’, and those that are ‘born digital’. Something is digitised when we create a digital representation of an analogue object – when we scan a document, or photograph a book.
A born digital resource – such as a piece of software, or a word processing document – came into existence within a computing system. We may later print out that word processing document to create an a physical copy, but the original object was, and remains, on our computer.
Processes for the creation, collection, preservation and management of these two types of digital resources can be quite different.
The scope and scale of digitisation
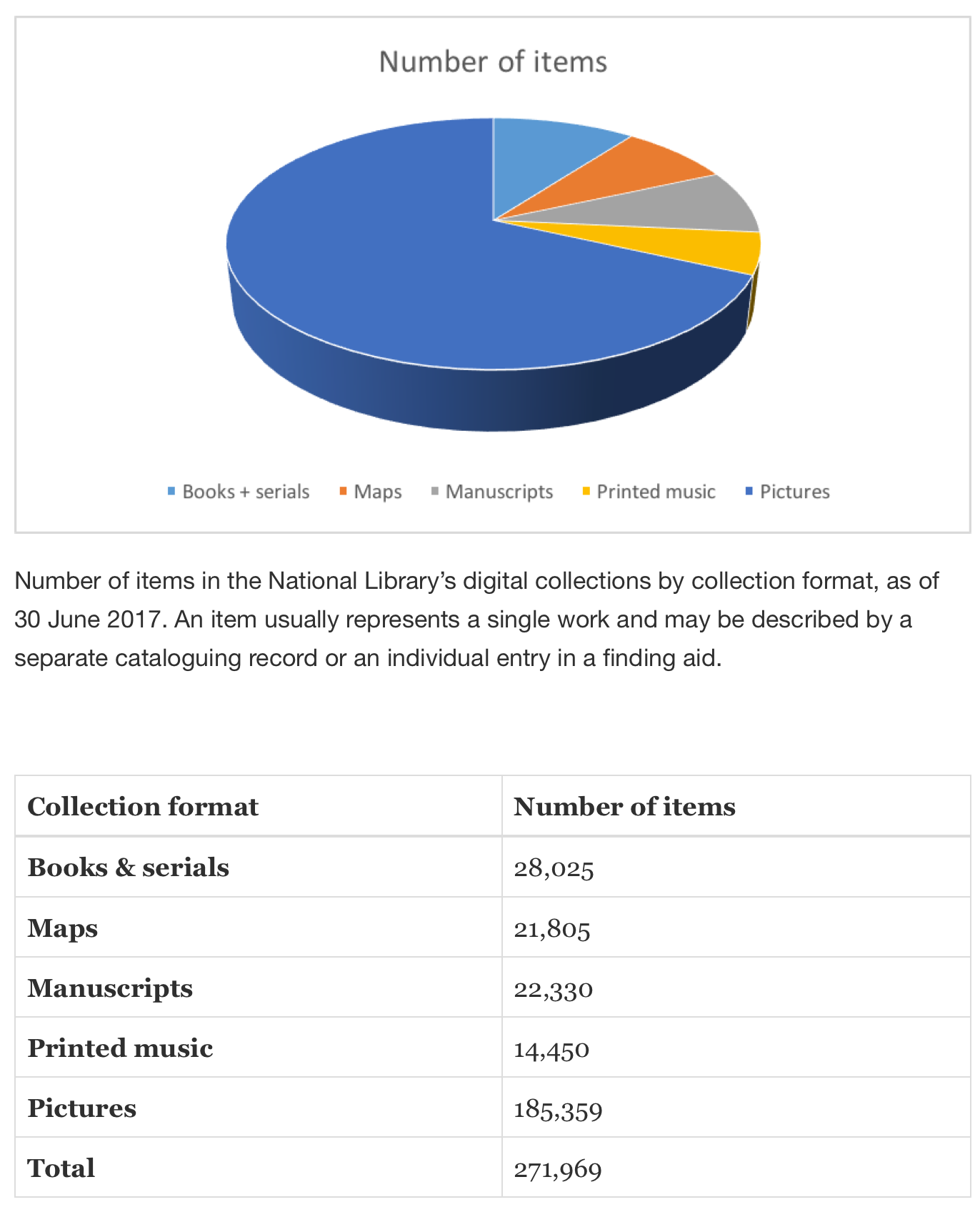
Remember when we had a look at the GLAM Innovation Study? They estimated that about 25% of the estimated 100 million objects in Australian museums and galleries had been digitised in some form. The National Archives of Australia estimates that it has created more than 27 million digital images of archival resources. As of June this year the National Library reported that it had digitised a total of 271,969 collection items (made up of 1,859,805 images). And of course that doesn’t include more than 200 million digitised newspaper articles in Trove.
Under it’s Digital Excellence program, the State Library of NSW is planning to create over 20 million collection images or pages.
Digitisation is now part of the core business of major collecting organisations. But does that mean we should just push ahead and digitise everything?
Yeah… Nah.
The ease with which we can access digital collections disguises the work involved in creating and managing them. Digitisation is an expensive business and the costs don’t stop once an image is made. If you ever get a chance to peek in the National Library’s server room you’ll see that Trove’s online newspapers have a huge physical footprint.
So decisions have to be made about what gets digitised and why. The National Archives of Australia lets users make some of these decisions. Its ‘digitisation on demand’ service means that if you request (and pay for) a copy of a file, that file is digitised and made publicly accessible through RecordSearch. This is combined with a ‘proactive digitisation’ service to digitise records that are highly-used or of known research value – such as the WWI service records. The digitisation of newspapers for Trove is guided by a selection policy with input from the national, state, and teritory libraries. The public can make suggestions as well.
Remember that chart showing the peak in Trove newspaper articles around 1914? Decisions have been made based on limited resources.
But even if money wasn’t a problem, would we want to digitise everything? Have a read of ‘Digitization: just because you can, doesn’t mean you should’ by Tara Robertson (and read the comments as well!). It raises a number of important ethical questions about the need to consult with affected communities. How does the digital environment challenge our ideas of consent and privacy? Should, for example, digitised collections like Trove’s newspapers remove articles about a person’s criminal convictions, or suicide attempts? On the one hand they’re already on the public record, but on the other digitisation makes them as easy to find as a simple Google search.
In Australia, cultural institutions pay careful attention to issues around the digitisation of Indigenous cultural materials. The Aboriginal and Torres Strait Islander Library, Information and Resource Network provides a set of protocols to guide projects and practices.
And then there’s copyright… Organisations undertaking large digitisation projects, such as Trove, often take what’s called a risk management approach. This is outlined in an article by Matthew Sag. Basically, there’s no practical way for organisations to be certain there’s no copyright restrictions on content in large digitisation projects – you just can’t check everything. Instead they have to weigh the risks of copyright infringement against the potential benefit of the digitised resource. While Trove has had few problems, other projects have not been so lucky. The British Library recently had to redact about 20% of the digitised content of the pioneering feminist magazine Spare Rib because of complaints regarding copyright and permissions.
Digitisation planning
Digitisation projects require careful planning to ensure that they’re responsible, cost-effective, and sustainable. There are plenty of guides available online for organisations undertaking such projects. For example:
-
Digitising your collections sustainably by Jisc provides links to a range of checklists, toolkits and case studies.
-
Digitising your collection is a series of blog posts by State Records NSW which provides a clear summary of both the planning and technical issues you need to consider.
-
Just digitise it is a training package developed the PROV for community groups.
The PROV guides sets out some basic questions that should be asked before undertaking any digitisation project:
- What will you digitise?
- How much will you digitise?
- How long will it take?
- How much will it cost?
- Who will do the work?
- How will you look after your new digitised collection?
The Jisc guide also emphasises the need to plan for sustainability – digitised collections require ongoing management, just like physical ones. Sustainability is also linked to use and impact – how can you demonstrate that digitisation provides good value? Resources such as the Balanced Value Impact Model provide a framework for measuring the value of digital collections. The Model defines impact as:
The measurable outcomes arising from the existence of a digital resource that demonstrate a change in the life or life opportunities of the community for which the resource is intended.
Obviously then you also need to be thinking about why you’re digitising stuff, and who is going to use your digital collections. Digitisation might be undertaken for a number of purposes, including:
- to help preserve collections by providing an alternative means of access;
- to enable specific research projects;
- to support internal management or business uses;
- to provide large-scale public access.
Each of these purposes might have its own set of justifications and measures of success.
Melissa Terras’s chapter ‘Cultural heritage information: artefacts and digitization technologies’ provides a good overview of the technological and policy frameworks within which digitisation projects are undertaken.
Portfolio alert! Read Terras’s chapter and the resources linked above while thinking about the factors that determine the success of a digitisation project. Imagine that you’ve been given the job of planning the digitisation of a large collection of material documenting the activities of political protest organisation that was active in the 1970s and 80s. The collection includes publications, posters, and photos, as well as unpublished letters and meeting notes. With worrying too much about detail, I want you to draw up a table that identifies possible costs, risks, and benefits (aim for at least 5 of each). Where there are risks, try to identify strategies that could minimise them. Write a minimum of 400 words, and add the finished table to your portfolio.
Digitisation processes
Having said all that, digitisation doesn’t need to be complicated. Developments in technology make it pretty easy for any organisation to create good quality digital collections. This video from PROV is aimed at community organisations and does a good job of demystifying the process.
Want to make your own book scanner with an old cardboard box and some duct tape? Here’s an online guide that will help you do just that.
Of course larger organisations will have access to more sophisticated technologies. Modern book scanners can even turn pages automatically without damaging the source materials. Here’s an example of the ‘high-end’ technology.
Digitisation beyond images
So far we’ve really talked about digitisation in terms of capturing images of physical objects. This is typically done using digital cameras or scanners. Those digital images might undergo further processing such as cropping or color correction.
But digitisation is not just about pictures. One of the most important technologies in opening up digital access to print collections is Optical Character Recognition or OCR. OCR finds text inside images and makes it available in a form that can be easily searched or manipulated. Trove’s 200 million newspaper articles are searchable because the text content has been extracted and saved using OCR. And they don’t have to be in English – Trove includes newspapers in a variety of languages, including Chinese!
But OCR has its limitations. A quick look on Trove will find plenty of examples where the text produced by OCR is pretty much unreadable. The accuracy of OCR is very much dependent on the quality of the source materials. Trove tries to get around this through people power – Trove users can easily correct dodgy OCR. It’s very simple:
-
Go to Trove’s digitised newspapers and find an article with dodgy OCR.
-
Hover over the line in the OCR text that you want to correct – you’ll see a little pencil icon appear.
-
Click on the pencil icon.
-
Log in using the Trove user account that you set up when you creating lists.
-
The line you’ve selected will then be highlighted. Just click in the box to start editing.
-
Click on another line to continue correcting.
-
Once you’ve finished just click Save & Exit.
-
Share the link to your corrected article on Slack.
Portfolio alert! Include the link to your corrected article in your portfolio. Feel free to do more than one – look at the text correctors’ hall of fame for inspiration!
Trove text correction is an example of ‘crowdsourcing’ – which is a broad and somewhat inaccurate term to describe ways in which organisations can seek the assistance of their users in enriching collection data. There are now lots of crowdsourcing projects in the cultural heritage domain – including The Real Face of White Australia!
As well as images and text recognition, there are a growing range of tools and techniques for creating digital representation of objects. A number of cultural institutions are experimenting with 3D imaging of their collections – this means they’re not just capturing how an object looks, they’re recording its spatial dimensions – it’s shape and size – as a digital model which can viewed from a variety of perspectives.
Have a browse of the Smithsonian’s collection of 3d models. Click on a thumbnail to open the object in a 3d viewer. Try rotating and zooming!
You may have seen some stories in the news describing some of the possibilities of more advanced digital imaging techniques – techniques that look below the surface of the object to see what we cannot. One group of scientists used 3d xray scanning to virtually unwrap an ancient scroll that had been severely damaged.
In Australia, the National Gallery of Victoria worked with scientists to apply a technique known as X-ray fluorescence to a 19th century portrait by French impressionist Edgar Degas. As a result they discovered a second portrait underneath the main one – all without any damage to the original. One of the scientists noted:
The technique is pretty well established but now that commercial scanners are coming out to do this kind of work I think it’s really going to take off and we are going to see a lot more of it.
These more advanced analytical techniques are also forms of digitisation.
Standards – of course!
Yes, we can’t discuss digitisation without at least some reference to our favourite topics – standards and metadata.
According to the SRNSW guide, the golden rule of digitisation is ‘capture once, use many times’. This means you should digitise your collections in a way which will support a range of uses – some you may not even have though of yet!
The easiest way to do that is to create a high-resolution master file which is carefully managed and preserved over time. The master file is then used to create ‘derivatives’ – lower resolution copies for particular purposes, such as online display. The SRNSW guide includes a useful section on understanding technical specifications.
But there’s no point creating wonderful images if you don’t also capture and preserve information about where they’ve come from and how they were created. Appropriate metadata is crucial to the management and long-term value of digital collections.
Born digital
Every now and then you’ll see a story pop up in the media about the ‘digital deluge’ or the looming dangers of a ‘digital black hole’. The argument is that we’re not doing enough to preserve contemporary online activity for future study – we’re in danger of losing many ‘born digital’ resources.
While we could always be doing more, these stories tend to overlook the fact that many people in the cultural heritage sector are actively grappling with these problems – new tools, technologies, and even new professions are emerging in order to preserve and make accessible our digital heritage.
For example, digital forensics is a new field that works with digital storage media to analyse and extract their contents. What would you do if a famous writer donated her computer and a set of floppy disks to your collection? Platforms like BitCurator provide a set of tools that enable cultural heritage professionals to view the contents of digital media without changing them. This is important as most operations on a computer leave some trace on the files themselves.
Digital archivists are designing systems that capture metadata at the point of creation to ensure that born digital records are embedded within systems of preservation and control. The National Archives of Australia has developed a Digital Continuity 2020 Policy, working towards the point at which all government business is conducted and recorded in digital form.
But how do you preserve ‘born digital’ records in a way that ensures they can still be accessed and used – after all technology is changing all the time!
There are a number of diferent approaches to the problem of access:
- you can try and preserve all of the hardware and software necessary to access digital objects;
- you can migrate the content of the digital objects into open and sustainable formats;
- you can create a software environment that emulates the original technology.
Each approach has its own strengths and weaknesses, and often institutions will use a combination of these techniques.
For example, one of the BitCurator case studies concerns the archives of the novelist Salman Rushdie. His collection includes a number of the computers used to write his novels. The Rose Library at Emory University now provides access to this born digital collection in two ways through a dedicated workstation. Researchers can browse a list of files that have been extracted and migrated from their original formats, but they can also interact with an emulation of Rushdie’s Macintosh Performa 5400 – using this emulation that can explore the author’s digital workspace, opening files using original software.
The possibilities of emulation have expanded considerably in recent years. It is now possible to run a functioning operating system within a web browser. Want to try? The Internet Archive includes a growing collection of software and games that you can explore.
-
Explore one of the early versions of Windows.
-
Try your hand at a classic MS-DOS game.
There are also a number of projects aimed at preserving online content, including websites and social media.
-
The Internet Archive also preserves a large part of the web, which you can explore using the Wayback machine.
-
The National Library of Australia maintains a selective web archive called Pandora – many significant Australian sites are preserved there (including my blog!).
-
The National Library also harvests Australian government websites. Using the Australian Government Web Archive you can hunt down all those controversial media releases that mysteriously disappear from politicians’ web sites.
-
The State Library of NSW is working with CSIRO to harvest social media content relating to specific events. Read this article about preserving tweets relating to the Martin Place siege.
Make your own web archive
One of the most useful things about the Wayback Machine is that little box on the home page that says ‘Save page now’. Just feed it a url and it will instantly attempt to archive the page. Once it’s done you have a permanent link to the contents of that page – so even if the page disappears from the original site, you’ll always be able to go back to the archive and view it. This is particularly useful if you want to cite webpages and are worried that they’re going to disappear.
So grab some urls and start archiving! What I want you to look out for are examples where the archiving process hasn’t quite worked. Examples of this might be content that’s dynamically loaded using javascript, or some embedded resources like videos. Does the Wayback Machine create a perfect copy?
Here’s an example:
- This is an exhibition of resources relating to the Chinese in NSW that was created by my partner Kate using my Trove Exhibition Builder.
- This, however, is what it looks like in the Wayback Machine.
As it loads, the exhibition pulls data dynamically from Trove to display individual items. But these requests aren’t captured by the Internet Archive, so it just shows the fallback version. Web archives are important digital collections, but they have their limits.
The problems of archiving dynamic content have lead to the development of new tools such as Webrecorder.io. This video gives a good introduction to the way it works:
Create a free account and record some web pages! Try some of the sites that didn’t work properly using the Wayback Machine and see if Webrecorder does the job. Try complicated sites with videos, or digital artworks. What works and what doesn’t?
Here’s Webrecorder’s version of the Chinese in NSW exhibition. Try navigating around the site.
Portfolio alert! Create an archive of a site using Webrecorder.io, share the link via Slack, and add it to your portfolio. In a minimum of 100 words report on the result. Do you think it provides an accurate representation? What might future historians miss out on?