
1. Trove is…#
1.1. Trove is not one thing#
If you ask people what Trove is, there’s a good chance they’ll talk about the digitised newspapers. And why not? The digitised newspapers have had an important impact on the way Australians access and understand the past. But Trove is more than newspapers. [Sherratt, 2021]
On the technical side, Trove is a combination of many interconnected systems, data sources, and interfaces, each with its own individual history.
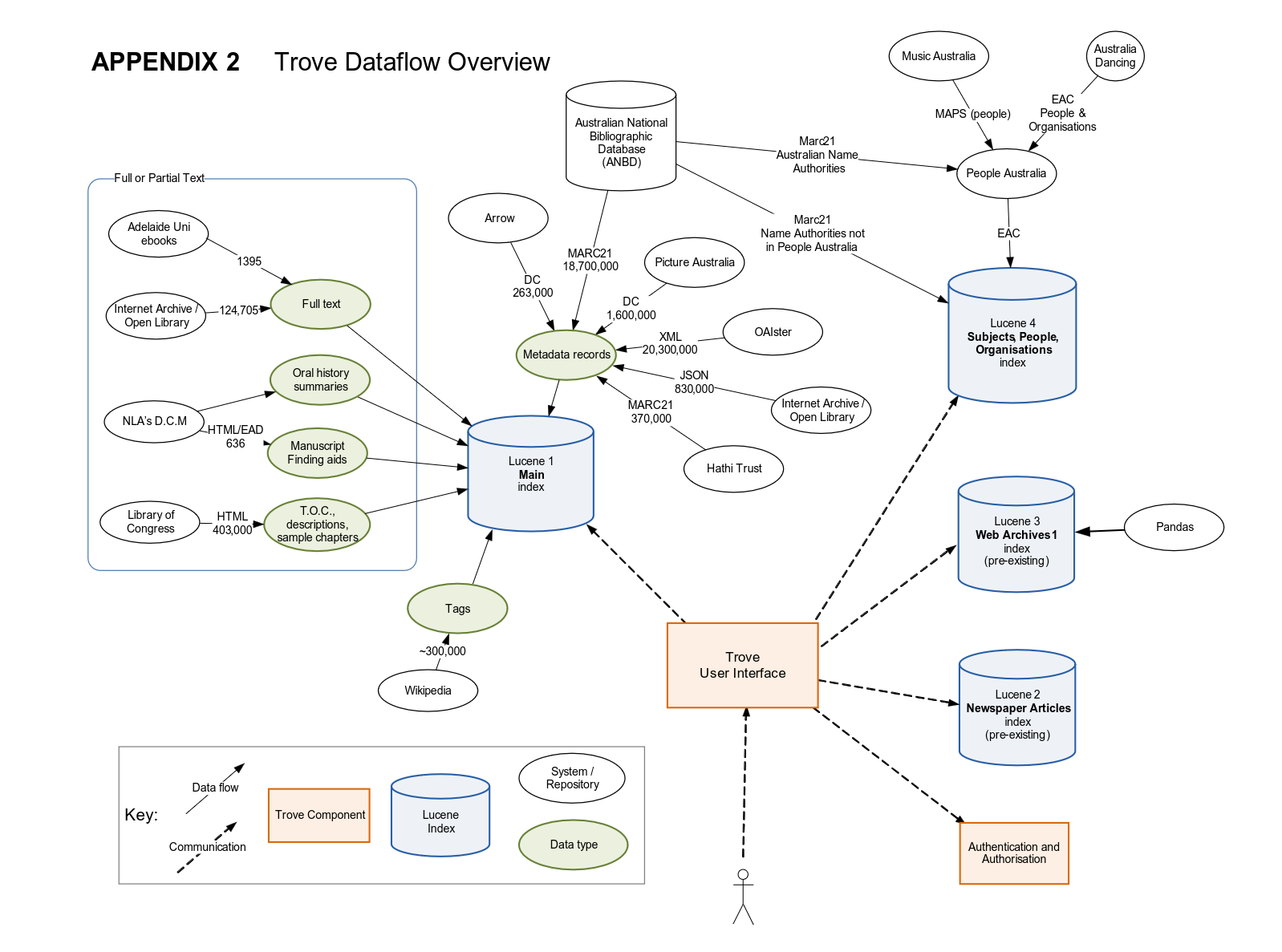
Fig. 1.1 Trove Data Flows, 2010, licensed CC-BY-NC. [Cathro and Collier, 2010] See the Trove help documentation for information about the current configuration.#
Trove began life as the Single Business Discovery Project at the NLA, and brought together many existing systems such as Libraries Australia, the Pandora web archive, the Register of Australian Archives and Manuscripts, Picture Australia, People Australia, and the Australian Newspapers beta service. From a users point of view these services have been mostly integrated, though some seams remain visible.
Trove is an ambitious attempt to provide Australians with facilitated access to research and heritage collections from across the country. It aggregates collection metadata from hundreds of organisations, big and small, and delivers it through a single search interface. Metadata contributors include libraries, archives, museums, galleries, universities, government agencies, and historical societies.
Trove is a platform for the delivery of digitised resources. It digitises the collections of the NLA and partners and makes them accessible online. As well as newspapers, there are books, photographs, oral histories, periodicals, parliamentary papers, ephemera, and manuscripts.
Trove is a repository for born-digital content. This includes the Australian Web Archive, which has been documenting Australia’s Internet history since 1996, and a rapidly growing collection of digital publications submitted through the National eDeposit service.
Trove is a space for collaboration, where users correct, enrich, organise, annotate, and share resources.
Trove is a platform for the development of new tools and services using data delivered through a series of Application Programming Interfaces (APIs).
And finally, as this Guide hopes to demonstrate, Trove is a source of data for innovative research in the humanities and social sciences – and beyond!
1.2. Trove is frustrating and unknowable#
But not everything works as you expect, and Trove doesn’t always deliver what you want in the form you need. Trove is often frustrating and confusing.
This Guide aims to help researchers make efficient and innovative use of Trove by documenting how it works and what it provides. But the complexity of Trove, and its evolution over time, makes it difficult to nail down its precise contents, limits, and structures. The simple question, ‘What’s in Trove?’, is not easily answered.
As I’ve grappled with topics such as Trove’s works and versions, and struggled to quantify measures like the number of pages missing from digitised newspapers, I’ve come to realise that Trove, as a whole, is effectively unknowable. It’s too big, too complex, and too inconsistent to yield to precise analysis. It’s also changing constantly, so any attempt to capture its contents will be immediately out of date.
Trove is what you make of it. The more you know about the systems and their limitations, the more you will be able to make effective use of the data it provides.
1.3. Trove now#
Trove is currently:
an aggregation of collection metadata from Australian GLAM and research organisations (includes pre-aggregated content through Libraries Australia as well as individually harvested collections)
a repository of digitised content from the NLA and partners, includes:
newspapers
journals and magazines
books
posters and ephemera
photographs
maps
manuscripts
oral histories
an archive of Australian web content from 1996 onwards
aggregated identity records for people and organisations
born-digital publications submitted via the National eDeposit scheme (access may be restricted to on-site use)
a platform for user engagement via tags, comments, lists, and OCR corrections
a series of APIs for delivering machine-actionable data