
17.4. Accessing data about newspaper & gazette titles#
What’s a title?#
‘Titles’ in this context refers to the names and details of the publications whose articles are digitised in Trove’s Newspapers & Gazette’s category. For example: Canberra Times, Sydney Morning Herald, or Commonwealth of Australia Gazette.
Title links and identifiers#
Every title in Trove’s Newspapers & Gazette’s category has it’s own unique identifier. You can find this identifier in the web interface and by using the Trove API.
You can browse a full list of titles in the web interface. Click on the 🛈 icon next to a title’s name to open its landing page.
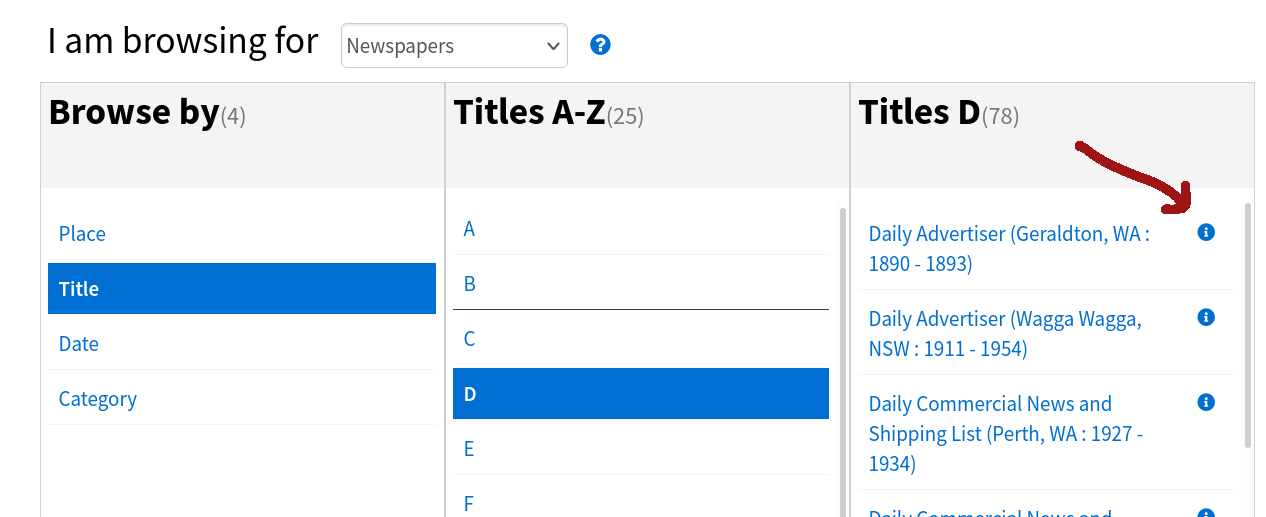
Fig. 17.9 Click on the 🛈 icon to open a title’s landing page#
If you’re viewing an article, you can get to the title’s landing page by hovering over the title in the breadcrumbs, and clicking on the ‘View title info’ link.
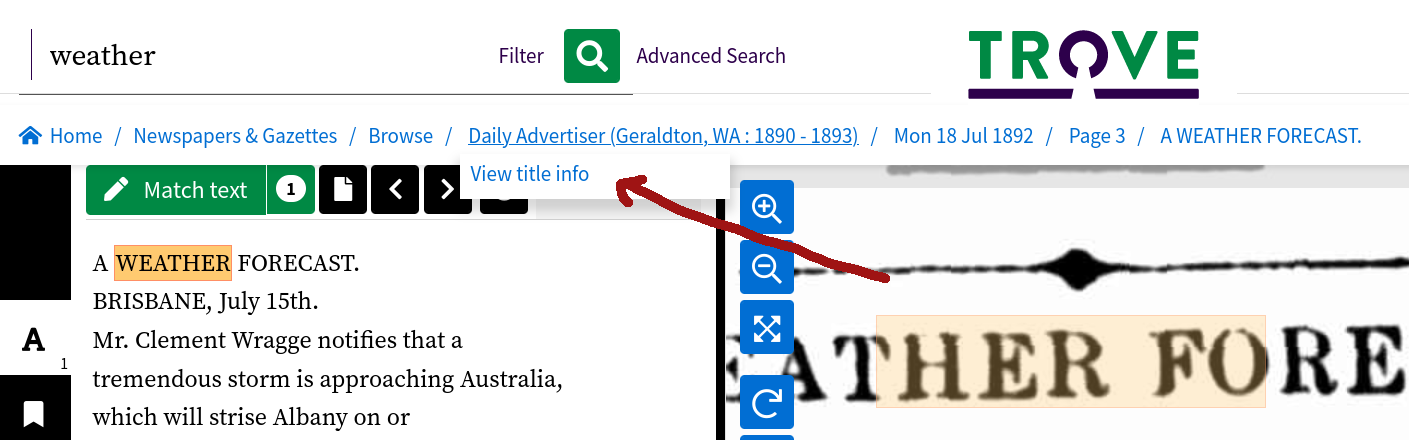
Fig. 17.10 Hover over the breadcrumbs to reveal a link to the title’s landing page#
The identifier is displayed on the title’s landing page and has the form: http://nla.gov.au/nla.news-title1406.
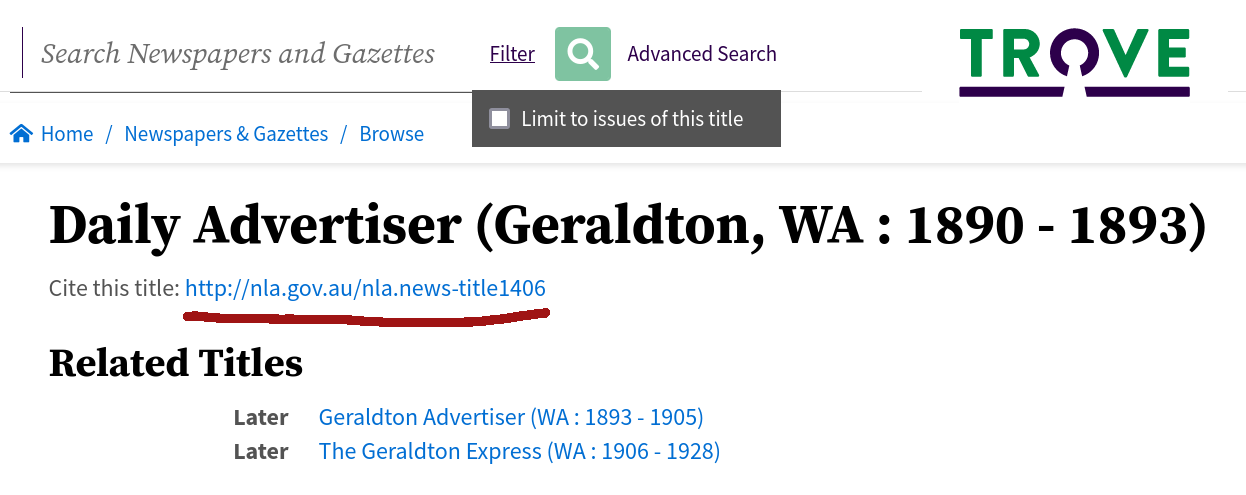
Fig. 17.11 The title’s identifier is displayed on the landing page#
If you load the identifier in your web browser, you’ll be redirected to the landing page. You’ll notice that the numeric part of the identifier is also in the url of the landing page.
You can access identifiers for all titles from the /newspaper/titles and /gazette/titles endpoints. You can also find them in the title field of an article record. For example:
"title": {
"id": "1406",
"title": "Daily Advertiser (Geraldton, WA : 1890 - 1893)"
},
The title["id"] field contains the title’s numeric identifier. By appending it to http://nla.gov.au/nla.news-title you can create a link to the title’s landing page, or by using it with the /newspaper/title endpoint you can download the title’s metadata from the Trove API.
Title metadata#
Get a list of newspaper & gazette titles#
You can get information about newspaper and gazette titles in Trove from these API endpoints:
newspaper/titles–
gazette/titles–
The data isn’t paginated, so you get all the titles at once. Here’s a basic example showing how to get a list of all the titles from the newspaper/titles endpoint.
import requests
# Set encoding parameter to JSON
params = {"encoding": "json"}
# Supply API key using headers
headers = {"X-API-KEY": YOUR_API_KEY}
# Make the request
response = requests.get(
"https://api.trove.nla.gov.au/v3/newspaper/titles", params=params, headers=headers
)
# Get the JSON data from the response
data = response.json()
# Get the list of newspapers
newspapers = data["newspaper"]
# Display the first title in the list
newspapers[0]
{'id': '166',
'title': 'Canberra Community News (ACT : 1925 - 1927)',
'state': 'ACT',
'issn': '18388671',
'troveUrl': 'https://nla.gov.au/nla.news-title166',
'startDate': '1925-10-14',
'endDate': '1927-12-16'}
How many newspaper titles are there?#
The responses you get back from the newspaper/titles or gazette/titles endpoints includes a total value that tells you the number of titles matching your request. Reusing the data from the request above, we can get the total number of newspaper titles like this:
data["total"]
1820
Get a list of newspaper titles from a particular state#
You can filter the list of titles by adding the state parameter. Possible values for state are:
nsw–
act–qld–tas–sa–nt–wa–vic–national–international–
Here’s an example showing how to get only newspapers published in Victoria.
import requests
# Add the state parameter and set it to 'vic' to get titles from Victoria
params = {"encoding": "json", "state": "vic"}
# Supply API key using headers
headers = {"X-API-KEY": YOUR_API_KEY}
response = requests.get(
"https://api.trove.nla.gov.au/v3/newspaper/titles", params=params, headers=headers
)
data = response.json()
newspapers = data["newspaper"]
# Display the first title in the list
newspapers[0]
{'id': '148',
'title': 'Advertiser (Hurstbridge, Vic. : 1922 - 1939)',
'state': 'Victoria',
'issn': '18380344',
'troveUrl': 'https://nla.gov.au/nla.news-title148',
'startDate': '1922-06-23',
'endDate': '1939-12-22'}
Get details of a single newspaper or gazette title#
To retrieve information about an individual title, use the newspaper/title or gazette/title endpoints with a title identifier. To construct the request url, add the title’s numeric identifier to the endpoint:
https://api.trove.nla.gov.au/v3/newspaper/title/[TITLE ID].
For example, to request metadata about the Canberra Times you’d use:
https://api.trove.nla.gov.au/v3/newspaper/title/11
Here’s how you’d retrieve metadata describing the Canberra Times:
import requests
# Numeric id of the title you want
title_id = "11"
request_url = f"https://api.trove.nla.gov.au/v3/newspaper/title/{title_id}"
# Add the state parameter and set it to 'vic' to get titles from Victoria
params = {"encoding": "json"}
# Supply API key using headers
headers = {"X-API-KEY": YOUR_API_KEY}
# Make the API request
response = requests.get(request_url, params=params, headers=headers)
# Extract the JSON data
data = response.json()
data
{'id': '11',
'title': 'The Canberra Times (ACT : 1926 - 1995)',
'state': 'ACT',
'issn': '01576925',
'troveUrl': 'https://nla.gov.au/nla.news-title11',
'startDate': '1926-09-03',
'endDate': '1995-12-31'}
You can use the newspaper/title and gazette/title endpoints to get information on what issues of a particular newspaper are available on Trove. By setting the include parameter to years, you get the total number of issues per year.
If you want more information on individual issues you need to set the range parameter to a specific date range.
Aggregate search results by title using the l-title facet#
You can also explore the characteristics of newspaper titles in Trove by using the API’s /result endpoint with category set to newspaper, and l-title set to the numeric identifier of a title. For example, to find out how many digitised articles from the Canberra Times are available on Trove, you can just make an API request without any search terms:
import requests
# Set the `l-title` parameter to a title's numeric id
params = {"category": "newspaper", "l-title": "11", "encoding": "json"}
# Supply API key using headers
headers = {"X-API-KEY": YOUR_API_KEY}
# Make the API request
response = requests.get(
"https://api.trove.nla.gov.au/v3/result", params=params, headers=headers
)
# Extract the JSON data
data = response.json()
# Find and display the total number of articles
total = data["category"][0]["records"]["total"]
print(f"There are {total:,} articles from the Canberra Times in Trove.")
There are 3,265,867 articles from the Canberra Times in Trove.
You can use facets such as decade, year, category, and illustrationType to examine other characteristics of an individual title.
The GLAM Workbench notebook Visualise Trove newspaper searches over time shows how you can use the decade and year facets with l-title to explore changes in a title over time, and even compare the content of different titles. This chart shows the number of articles containing the term ‘worker’ in three different newspapers, the Tribune, the Sydney Morning Herald, and the Sydney Sun.
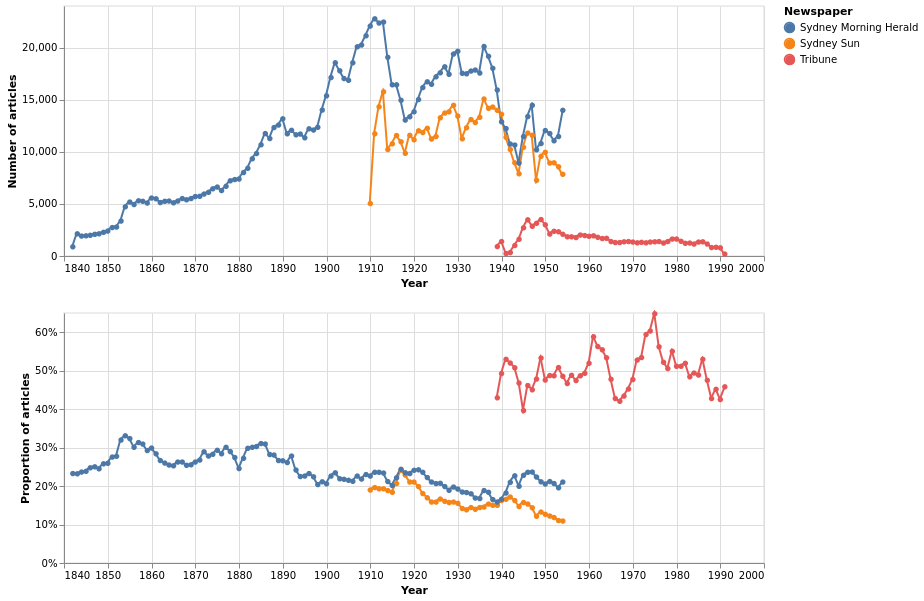
Fig. 17.13 The raw number and proportion of articles containing the term ‘worker’ by year in the Tribune, Sydney Morning Herald, and Sydney Sun#
Find catalogue entries for newspaper titles#
==Update this section once search and books sections are done==
use ISSNs to search in “Books & Libraries”
note that the
issnfield in API records doesn’t always contain ISSNssearch for
format:Periodical/Newspaper, add filters such as “nla.gov.au/nla.news” and “trove.nla.gov.au”, weed out journals and eDeposit (how many are there?)
Title text#
With the exception of some Government Gazettes which are available as bulk downloads, there’s no direct way of accessing all the text of a title. You’d need to use the /result endpoint to assemble a collection of articles and then aggregate the OCRd text from the individual articles. This could be done issue by issue, or by setting the l-title facet without a search query, and then harvesting the complete result set.
Depending on the title, this could take a significant amount of time and generate a large amount of data. You might want to use the Trove Newspaper & Gazette Harvester for a job like this.
Images and PDFs from titles#
There’s no direct method for downloading all the images or PDFs from a newspaper title in Trove. However, there are methods for getting issues as PDFs and assembling a collection of front page images.
Downloading every issues as a PDF#
If you have an issue’s identifier you can download it as a PDF. You can get a complete list of issue identifiers for a title from the /newspaper/title endpoint. So it’s possible to work through all the issue identifiers to download every issue of a title as a PDF. This method is documented in the GLAM Workbench notebook Harvest the issues of a newspaper as PDFs.
Downloading pages as images or PDFs#
To download pages from a newspaper in Trove, you’d need to assemble a collection of page identifiers. If all you want are the front pages of a newspaper, you can obtain the page identifiers from the issue metadata.
If you want more pages, you’d could try using the /result endpoint with the l-title facet to download the metadata from every article in a newspaper. You’d also need to set the reclevel parameter to full to include the page identifiers in the article records. You could then extract the page identifiers from the article records and remove any duplicates. However, there’s no guarantee that this method will find every page as it depends on how the articles are indexed.
Once you have assembled a collection of page identifiers you can download the pages as images or PDFs.